lubridate month() + wday()
in lubridate
September 26, 2020
Art by Allison Horst @allison_horst
When I am trying to work out a problem with R, I generally skip the package documentation, I avoid stack overflow, and I go straight for a blog post written by someone who has just learned what I am trying to learn.
I think when you have just learned something, you are in THE BEST PLACE to teach someone else. You are acutely aware of what it feels like to not “get it”. You have only very recently worked out the pinch points and stumbling blocks, so you are well positioned to write in a way that allows another beginner to avoid all that.
In contrast, package documentation is written by the developer who knows WAY TOO MUCH about the intricacies of how it works under the hood to have much empathy for someone who knows nothing. And stack overflow is full of experts who suffer from the curse of knowledge and deliver base R solutions in a condescending tone.

When I found Julia’s Silge’s post about lubridate I was immediately excited because I knew that I could learn A LOT about how lubridate works by finding an interesting dataset and emulating her post.
COVID cases have been really low in NSW in the last couple of weeks after a bit of a spike back in July-August, but the Chief Health Officer has been warning about not becoming complacent because testing rates have also been declining.
This data comes from NSW health and contains the number of tests conducted throughout NSW each day by age group during the pandemic. There should be date data to deal with.
load packages
library(tidyverse)
library(here)
library(ggeasy) # for easy ggplot editing
library(harrypotter) # for palettes
options(scipen = 999)
library(lubridate)
##
## Attaching package: 'lubridate'
## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, union
I usually ask .Rmd to not even show me these package loading messages by setting the chunk options to warning = FALSE, messages = FALSE, but this warning could be the source of some issues I have had with lubridate in the past.
The lubridate package has a here() function that messes with the here() function from the here package. If you are going to use lubridate and here in the same analysis, you need to remember to use here::here() to avoid problems.
literally no chill tonight. or ever, really. pic.twitter.com/UqnfPtcTl4
— Jesse Mostipak (@kierisi) April 2, 2020
apparently the next version of lubridate won’t have a here() function, when is that coming out?
read in the data
tests <- read_csv("testing_agg.csv")
check data types
glimpse(tests)
## Rows: 1,635
## Columns: 3
## $ test_date <date> 2020-03-09, 2020-03-09, 2020-03-09, 2020-03-09, 2020-03-09…
## $ age_group <chr> "AgeGroup_0-9", "AgeGroup_10-19", "AgeGroup_20-29", "AgeGro…
## $ test_count <dbl> 238, 386, 688, 779, 621, 582, 344, 261, 207, 383, 803, 917,…
Nice! the date column is in date format, that doesn’t always happen with my data in the wild.
why does R sometimes auto-recognise dates and other times not?
Lets look at the first few rows of the dataframe. Looks like we have test counts each day for separate age groups. I’m not interested in age at the moment, but I would like to know how testing rates have changed over the past few months.
head(tests)
## # A tibble: 6 × 3
## test_date age_group test_count
## <date> <chr> <dbl>
## 1 2020-03-09 AgeGroup_0-9 238
## 2 2020-03-09 AgeGroup_10-19 386
## 3 2020-03-09 AgeGroup_20-29 688
## 4 2020-03-09 AgeGroup_30-39 779
## 5 2020-03-09 AgeGroup_40-49 621
## 6 2020-03-09 AgeGroup_50-59 582
Start by making a dataframe with getting the total tests conducted each day across age groups.
total_tests <- tests %>%
group_by(test_date) %>%
summarise(test_count = sum(test_count))
getting months/days
lubridate has functions that will pull the day, month or year from a variable in date format. Following in Julia’s footsteps here.
today()
## [1] "2022-01-15"
year(today())
## [1] 2022
month(today())
## [1] 1
day(today())
## [1] 15
Lets use the month() function to count how many tests have been conducted in each month since the beginning of the pandemic.
total_tests %>%
group_by(month(test_date, label = TRUE)) %>%
summarise(month_tests = sum(test_count))
## # A tibble: 7 × 2
## `month(test_date, label = TRUE)` month_tests
## <ord> <dbl>
## 1 Mar 106256
## 2 Apr 147130
## 3 May 278052
## 4 Jun 388739
## 5 Jul 622984
## 6 Aug 721733
## 7 Sep 210431
It looks like we really stepped up the testing in July and August but the NSW Chief Health Officer is right, September rates are really low. Lets plot that…use label = TRUE to include month names rather than numbers.
Make a new df that summarises the total tests conducted each month.
month_summary <- total_tests %>%
group_by(month(test_date, label = TRUE)) %>%
summarise(total_tests = sum(test_count)) %>%
rename(covid_month = 'month(test_date, label = TRUE)')
plot total tests by month
month_summary %>%
ggplot(aes(x = covid_month, y = total_tests, fill = covid_month)) +
geom_col() +
scale_fill_hp_d(option = "LunaLovegood") +
scale_y_continuous(limits = c(0, 800000), expand = c(0,0)) +
labs(title = "Total number of COVID tests conducted in NSW \n each month", x = "Month", y = "Total tests", caption = "data downloaded from https://data.nsw.gov.au/nsw-covid-19-data (28-9-2020)") +
theme_classic() +
easy_remove_legend()
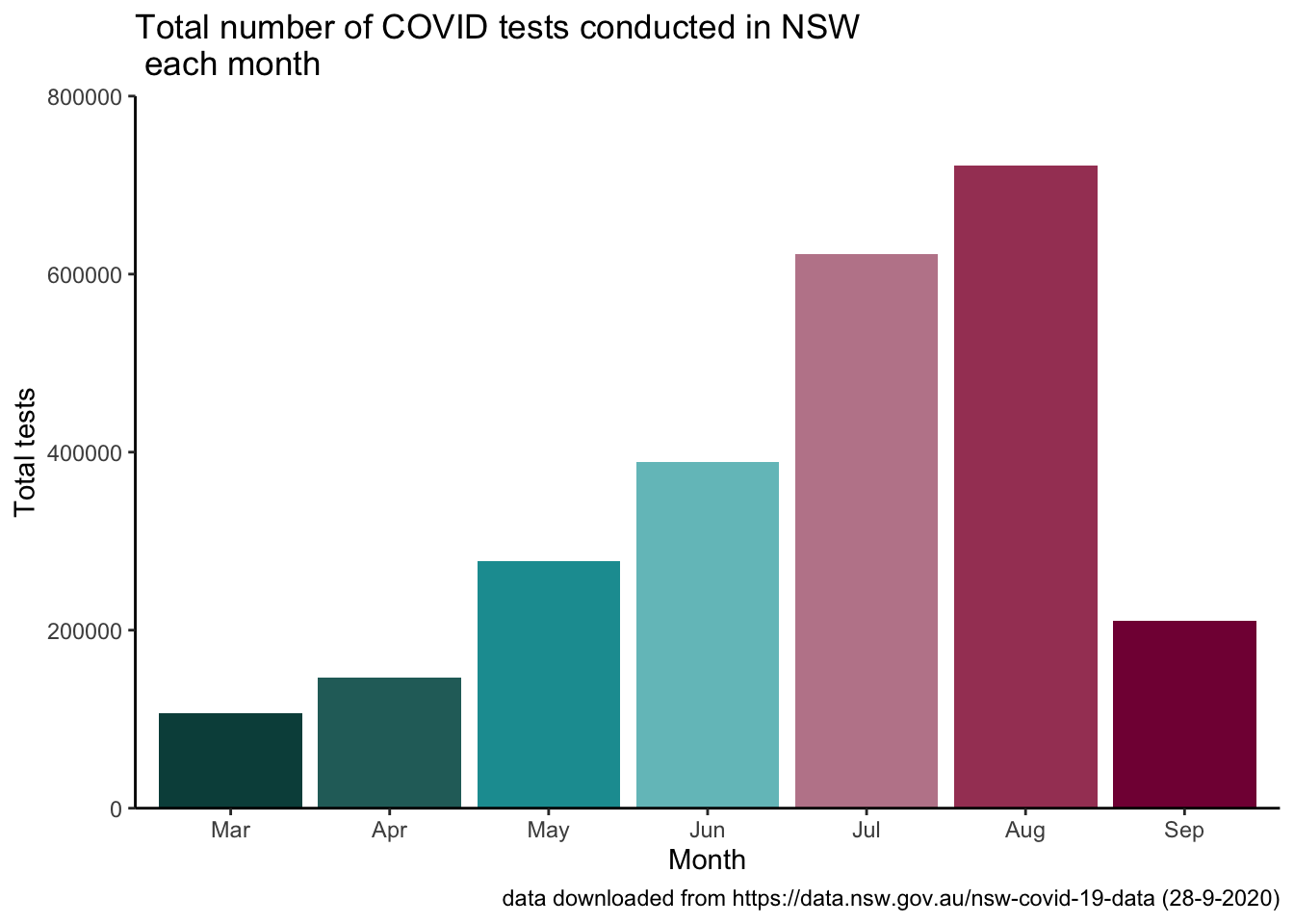
Yikes September total tests are REALLY low, there is still a few days left but still…
The health officials are always talking about variability in the number of new cases might be related to when the tests are conducted. I wonder whether there is a pattern in the number of tests conducted across the week. lubridate has a wday() function that works a lot like month() to allow you to summarise by day of the week.
Make a new df that summarises the mean number of tests conducted each day of the week.
wday_summary <- total_tests %>%
group_by(wday(test_date, label = TRUE)) %>%
summarise(mean_tests = mean(test_count)) %>%
rename(covid_day = 'wday(test_date, label = TRUE)')
plot mean tests each week day
wday_summary %>%
ggplot(aes(x = covid_day, y = mean_tests, fill = covid_day)) +
geom_col() +
scale_fill_hp_d(option = "HermioneGranger") +
scale_y_continuous(limits = c(0, 20000), expand = c(0,0)) +
labs(title = "Mean number of COVID tests conducted in NSW \n each weekday", x = "Week day", y = "Total tests", caption = "data downloaded from https://data.nsw.gov.au/nsw-covid-19-data (28-9-2020)") +
theme_classic() +
easy_remove_legend()
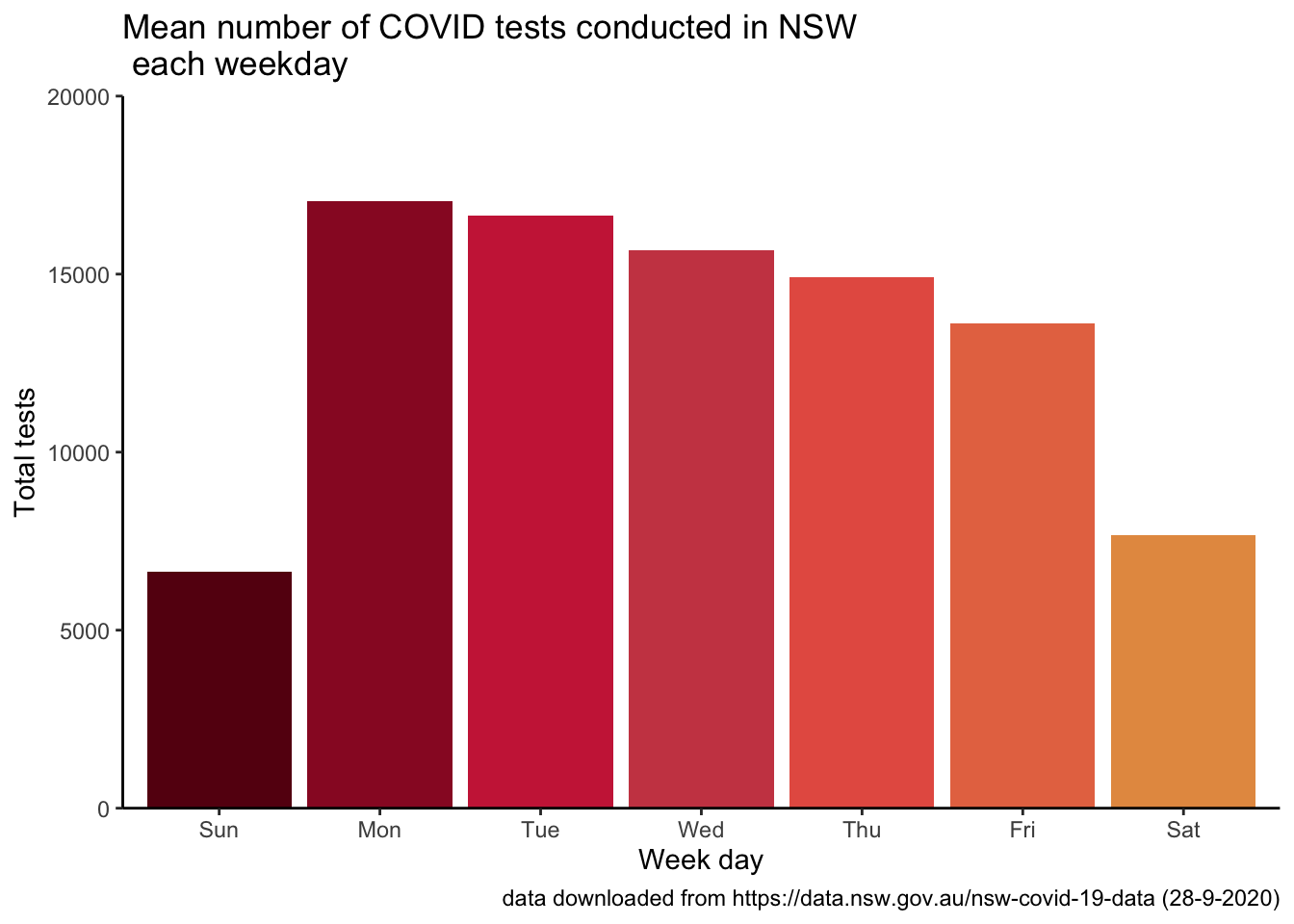
Looks like testing rates decline across the working week, and are definitely much lower in the weekend. I wonder whether that pattern has changed across the pandemic.
Make a new df that summarises the number of tests conducted by day of the week for each month. Use week_start = getOption("lubridate.week.start", 1) to make Monday the start of the week.
wday_month_summary <- total_tests %>%
mutate(covid_day = wday(test_date, week_start = getOption("lubridate.week.start", 1), label = TRUE)) %>%
mutate(covid_month = month(test_date, label = TRUE)) %>%
group_by(covid_day, covid_month) %>%
summarise(mean_tests = mean(test_count, na.rm = TRUE))
plot mean tests each week day by month
wday_month_summary %>%
ggplot(aes(x = covid_day, y = mean_tests, fill = covid_day)) +
geom_col() +
scale_fill_hp_d(option = "DracoMalfoy") +
facet_wrap(~covid_month) +
scale_y_continuous(limits = c(0, 35000), expand = c(0,0)) +
labs(title = "Mean number of COVID tests conducted in NSW \n each week day across the pandemic",
x = "Week day", y = "Total tests",
caption = "data downloaded from https://data.nsw.gov.au/nsw-covid-19-data (28-9-2020)") +
easy_remove_legend()
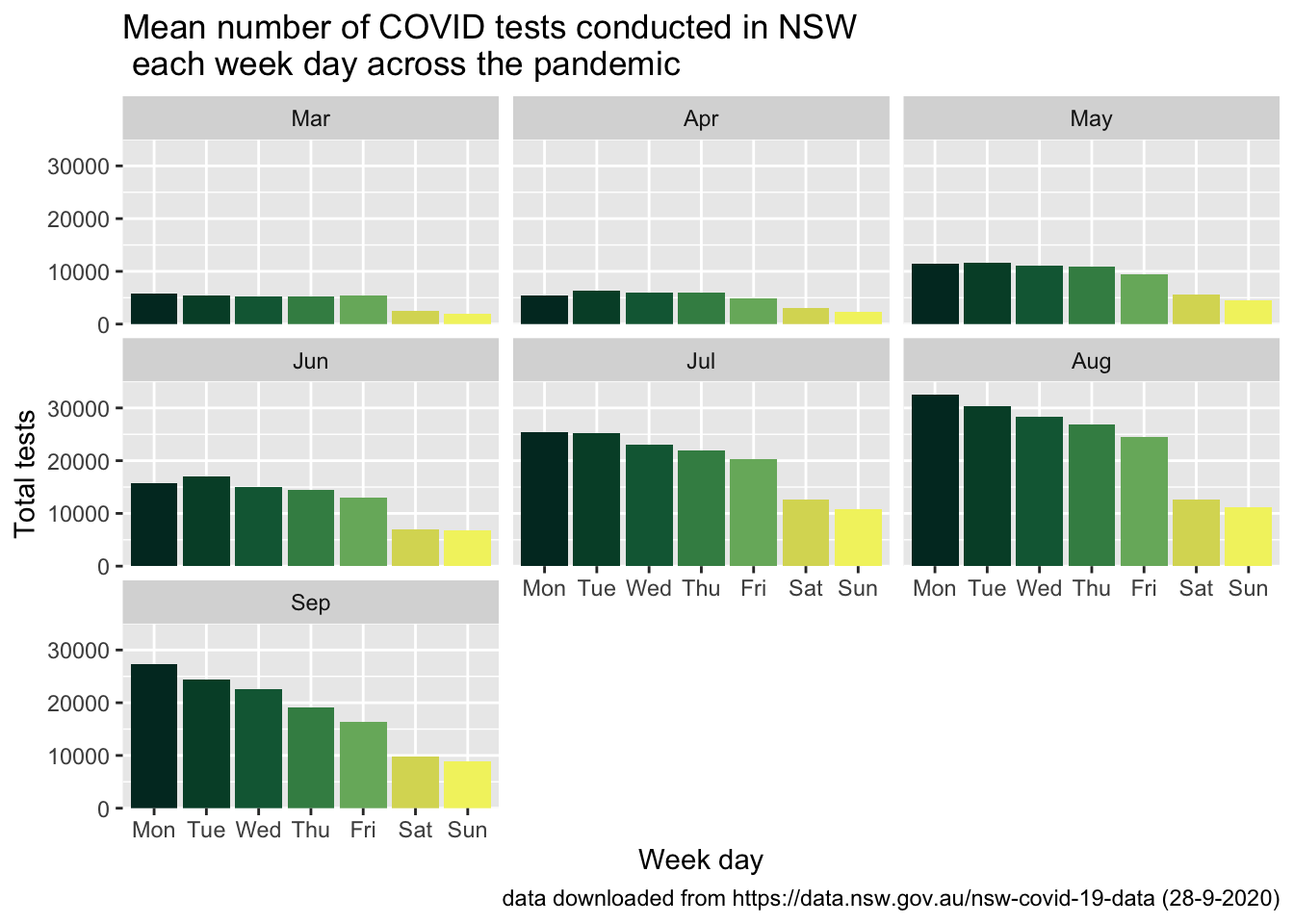
geom_col() makes it difficult to see how testing rates might have changed across the pandemic. Lets look at just July - September.
plot mean tests each week day July - Sept
wday_month_summary %>%
filter(covid_month %in% c("Jul", "Aug", "Sep")) %>%
ggplot(aes(x = covid_day, y = mean_tests,
colour = covid_month, group = covid_month)) +
geom_point(size = 3) +
geom_line() +
scale_colour_hp_d(option = "RonWeasley") +
scale_y_continuous(limits = c(0, 35000), expand = c(0,0)) +
labs(title = "Mean number of COVID tests conducted in NSW \n each weekday in the past 3 months", x = "Week day", y = "Mean tests", caption = "data downloaded from https://data.nsw.gov.au/nsw-covid-19-data (28-9-2020)") +
theme_classic() +
theme(
legend.position = c(.98, .98),
legend.justification = c("right", "top"),
legend.box.just = "right",
legend.margin = margin(6, 6, 6, 6)
)
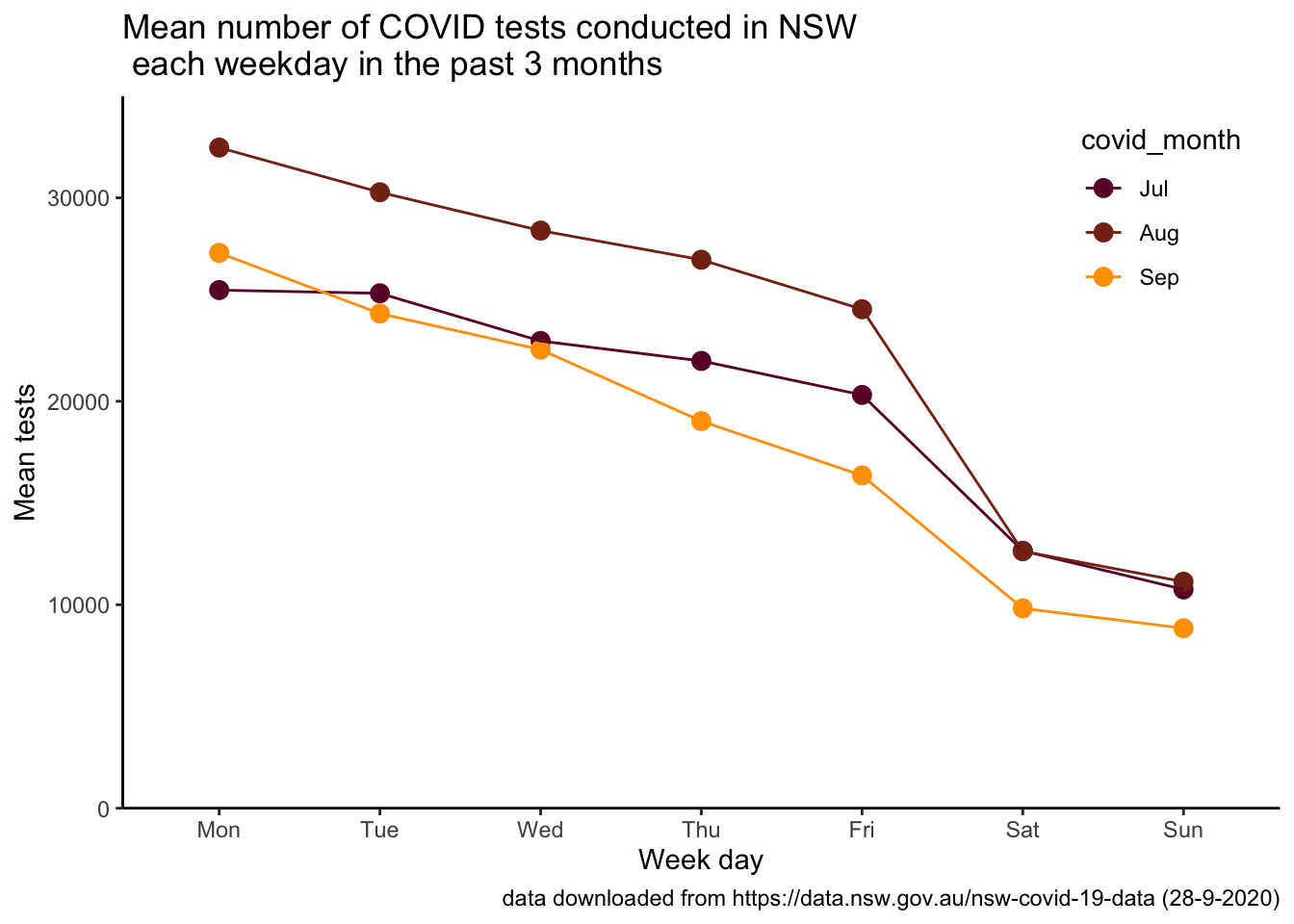
Interesting… looks like testing rates in Sept are the same as in Aug (but lower than July) early in the week, but fewer people are being tested as the week goes on.
How many fewer tests are we doing each day in Sept relative to July levels?
Using the day() function instead of wday() to plot the tests each day across the month.
total_tests %>%
filter(month(test_date, label = TRUE) %in% c("Jul", "Aug", "Sep")) %>%
ggplot(aes(x = day(test_date), y = test_count, fill = wday(test_date, label = TRUE, week_start = getOption("lubridate.week.start", 1)))) +
geom_col() +
facet_wrap(~month(test_date, label = TRUE)) +
scale_fill_hp_d(option = "LunaLovegood") +
scale_y_continuous(limits = c(0, 40000), expand = c(0,0)) +
labs(title = "Daily COVID tests conducted in NSW in July-Sept", x = "Month", y = "Tests per day", caption = "data downloaded from https://data.nsw.gov.au/nsw-covid-19-data (28-9-2020)") +
theme_classic() +
easy_remove_legend_title()
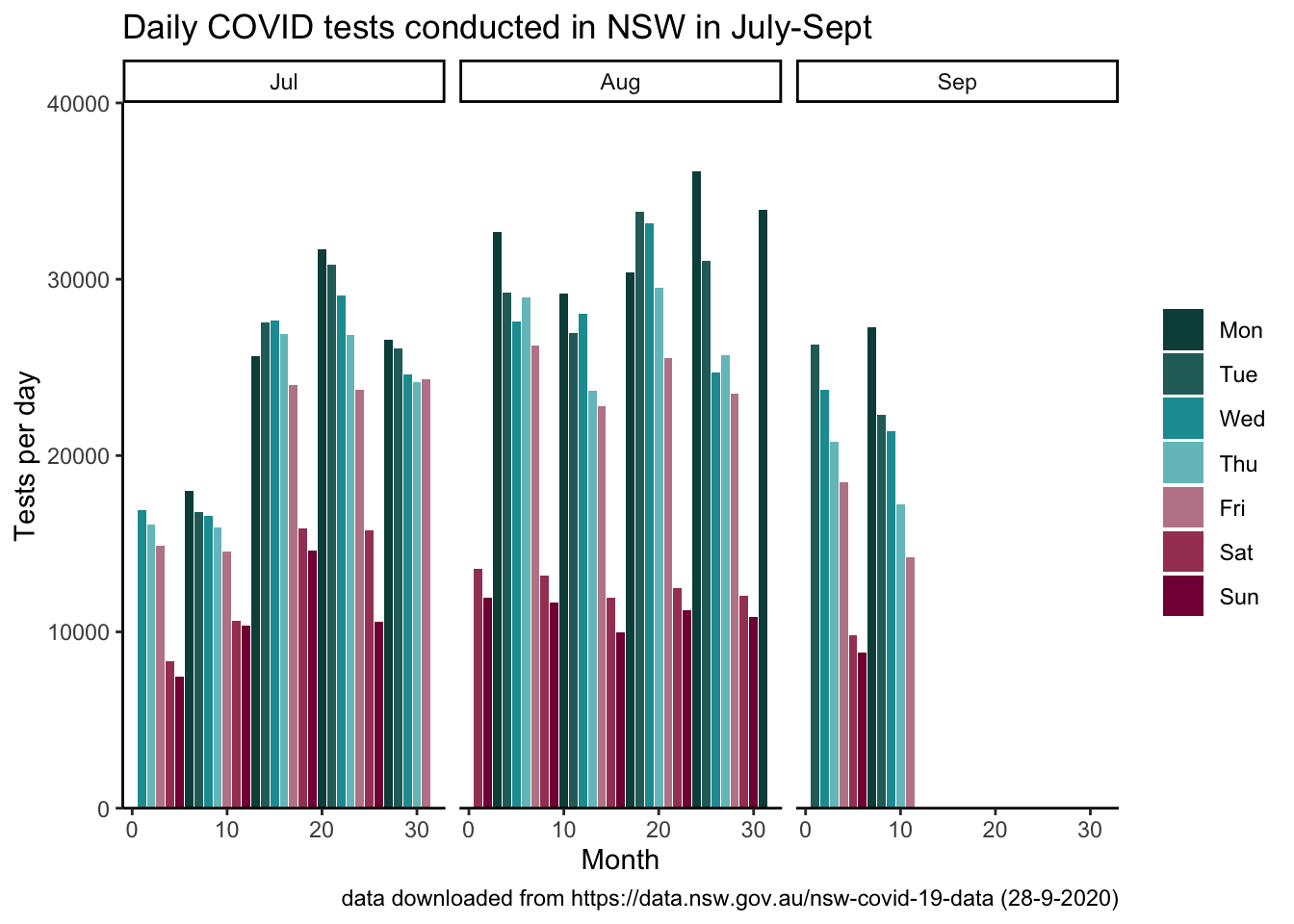
Oh!!!
The data I downloaded 28-9-2020 is incomplete. Even though the website says this data is updated every day, the total tests for Sept are bad because we only have data up until 11-9-2020.
What have I learned about lubridate thus far
-
sometimes R automatically recognises your date variables as dates, but I’m not sure why this happens really infrequently with my real world data- probably related to d-m-y format not being the R default
- how to make it more likely that R will read my dates as dates
- how to convert dates that R thinks are characters into date format
-
lubridate functions like
day(),w_day(),month()andyear(), make it easy to work with date components as ordinal factors- use
label = TRUEwhen using these functions to use labels rather than numeric values - use
week_start = getOption("lubridate.week.start", 1)to change the default from the week starting on Sunday to starting on Monday
- use
-
lubridate still clashes with the here package; if you are using both you need to specify
here::here(). Find out when lubridate will no longer have ahere()function.