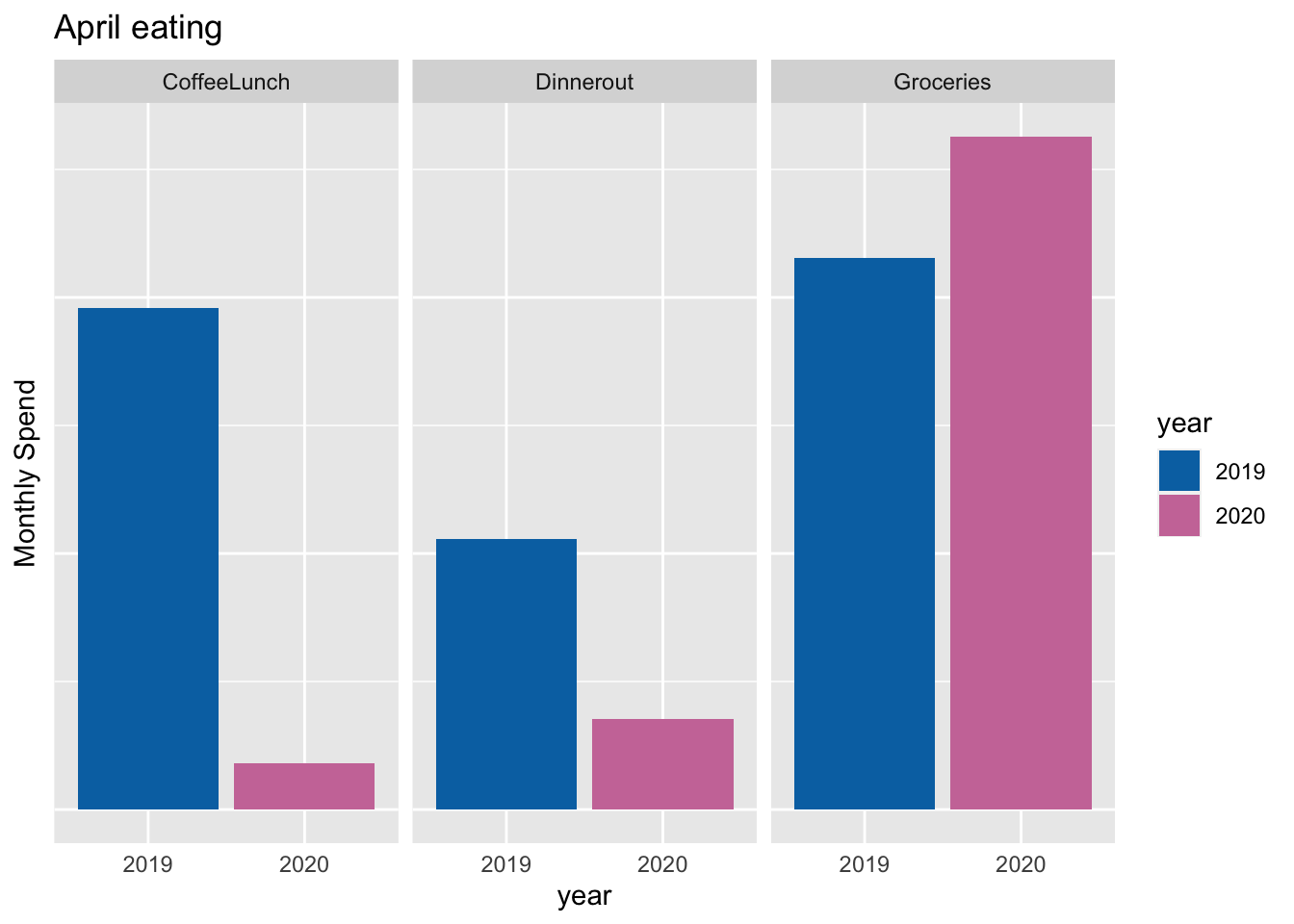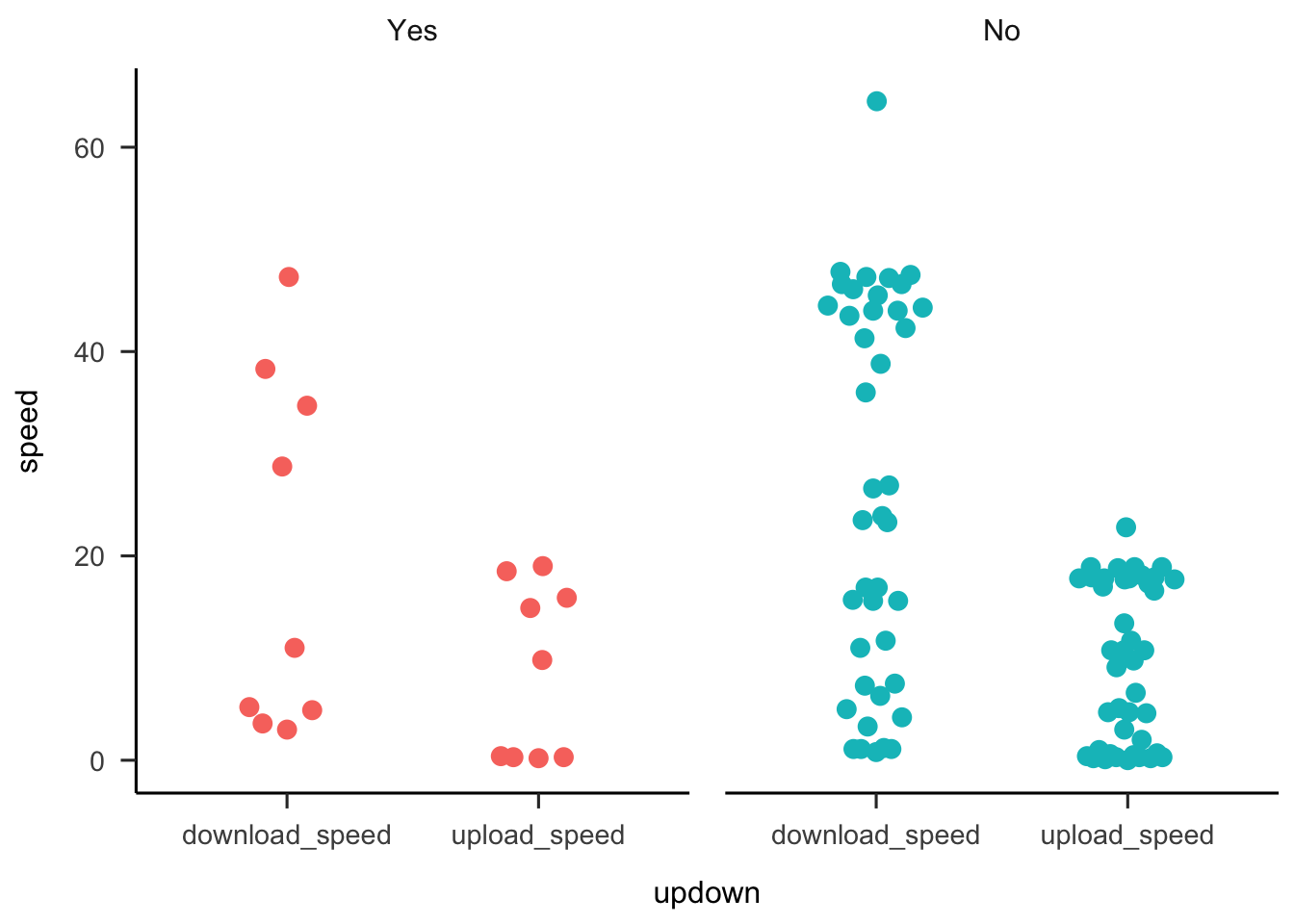
ggplot tricks
Here are some ggplot tricks that I shared at the R-Ladies Sydney June Show and Tell. Why is my internet speed so terrible? Working from home and pivoting to teaching online has made me realise that my wifi connection is really bad, particularly when it rains. I have been teaching new honours students R and needed a little dataset to demo how to get data into R, so made a google form and put it out on twitter to confirm to myself that my connection really is worse than most other people.